











 查看 Markdown
查看 Markdown在金融行业做风控,规则往往是最不缺的东西。多年的业务经验、合规要求和风险事件,早已沉淀出一套套判断逻辑。银行和保险团队真正缺的,是一套能让这些规则在实时链路里稳定运行的机制。
大额转账应该秒级拦截,结果还在等离线任务;改密后立即转账、暴力破解登录、同事故多人理赔,本来应该第一时间打标,结果要跨好几个系统补逻辑;规则改得频繁,但每次调整都得改代码、重新发版、重新联调,最后大家都不敢轻易动。
很多高价值风险本身并不复杂,判断逻辑用规则就能清楚表达:单笔大额转账、24 小时频繁小额分拆、1 小时内地理位置异常交易、30 分钟密码连续错误、30 天内多头借贷、投保后 90 天内理赔、同一事故 3 个以上关联理赔人。这些规则的要求不在于复杂,在于实时、稳定、可改、可解释。
我们整理了一套银行和保险风控样例,在 Easysearch 2.1.2 测试环境里走通了完整链路,记录下来,供参考。
先看结论 #
- 规则数:
24 - 覆盖场景:银行交易、反洗钱、账户安全、信贷、保险理赔
- 规则编译耗时:
415ms - 单规则样本验证:
24 / 24命中 - 混合业务流样本:
8条,命中6条,未命中2条(正常事件)
写入后会直接输出结构化风险字段,包括是否命中、命中规则 ID 列表、命中条数和最高风险等级,下游系统可以直接用这些字段做决策,不需要再自己解析。
规则引擎在链路里承担什么 #
这套方案把整条链路分成三层:上游特征系统负责计算窗口聚合、账户画像、名单命中和关系特征;Easysearch 规则引擎负责实时命中和结构化输出;下游处置系统负责拦截、二次验证、人工复核和告警推送。
规则引擎不负责自己做历史聚合。类似 acct_txn_cnt_24h(24 小时内交易笔数)、loan_apply_org_cnt_30d(30 天内申请机构数)、txn_geo_distance_km_1h(1 小时内地理距离)这些字段,都由上游流式计算或特征服务预先算好,再作为扁平字段写进当前事件文档。规则引擎要做的,是把"当前事件 + 已计算特征"快速转成风险结果。
这个分工明确之后,规则本身的维护和规则引擎的边界就都清楚了。
把这套实时风控链路拆开看,核心就是五步:事件接入、特征补齐、规则编译、在线匹配、结果输出与处置。下面这张图把银行和保险场景里这条链路的分工关系完整串起来了。
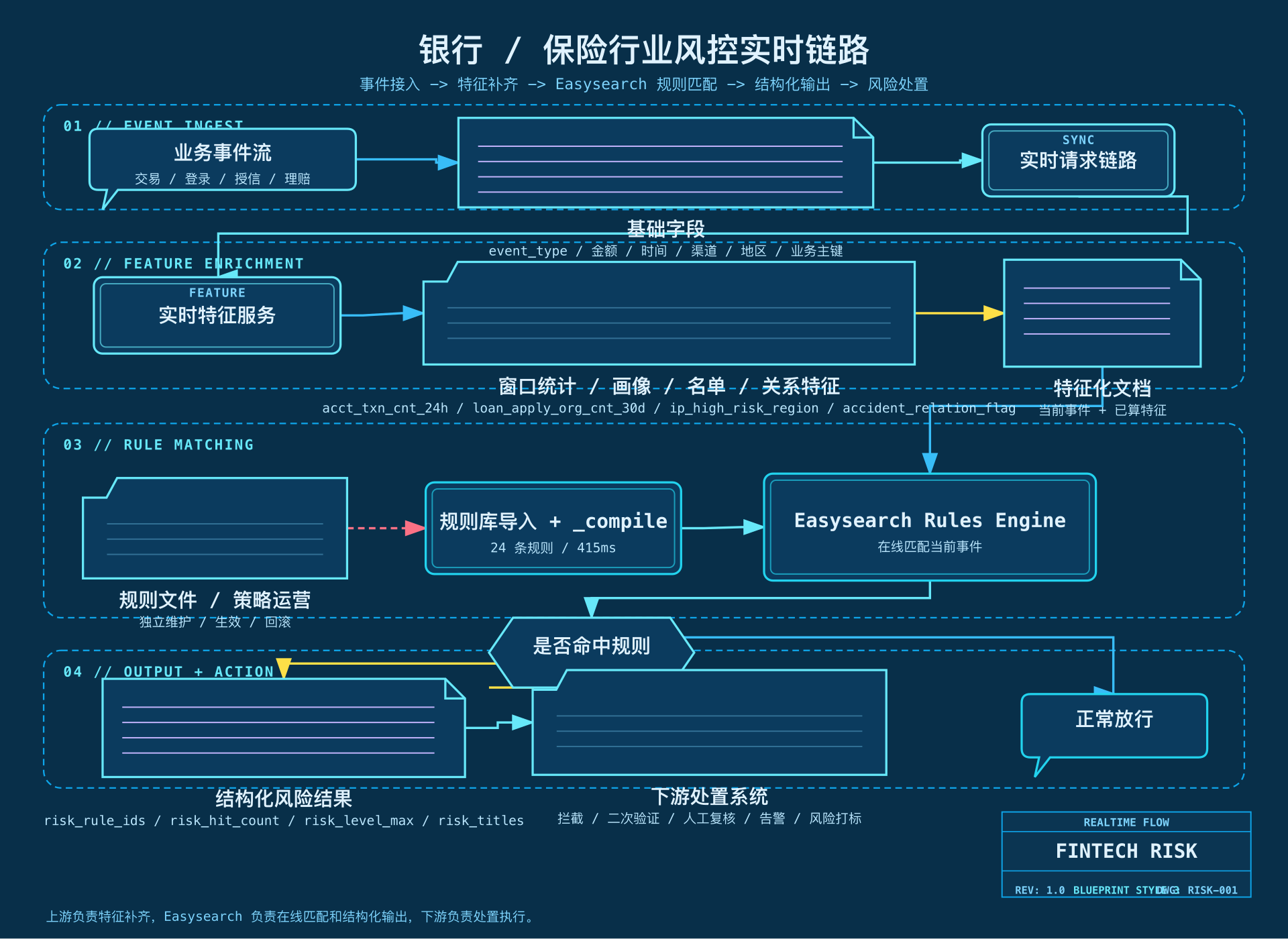
规则覆盖的五类场景 #
| 场景 | 示例规则 |
|---|---|
| 银行交易 | 大额转账、深夜大额转账、新账户大额流出 |
| 反洗钱 | 小额分拆、资金归集后转出、休眠账户激活 |
| 账户安全 | 暴力破解、撞库、改密后立即转账 |
| 信贷风控 | 多头借贷、还款日前余额骤降、收入还款压力过高 |
| 保险理赔 | 投保后短期出险、频繁小额理赔、同事故多人理赔 |
规则文件的一部分如下:
event_type{{txn}} and biz_line{{bank}} and txn_type{{transfer}} and txn_amount{r{50000,}} T01|HIGH|bank|大额转账触发
event_type{{txn}} and biz_line{{bank}} and acct_txn_cnt_24h{i{10,}} and txn_amount{r{,9999.99}} and acct_txn_sum_24h{r{50000,}} T02|HIGH|bank|24小时频繁小额分拆
event_type{{login}} and biz_line{{security}} and login_pwd_fail_cnt_30m{i{5,}} S01|HIGH|security|30分钟密码错误过多
event_type{{loan_apply}} and biz_line{{credit}} and loan_apply_org_cnt_30d{i{3,}} C01|HIGH|credit|30天多头借贷
event_type{{claim}} and biz_line{{insurance}} and accident_related_claimant_cnt{i{3,}} and accident_relation_flag{{1}} I03|HIGH|insurance|同事故多人关联理赔
这里的关键不是语法,而是输入文档的口径。规则匹配的不是原始流水文本,而是已经做过特征化处理的事件文档。比如下面这条样本,已经补齐了 24 小时统计特征:
{
"event_type": "txn",
"biz_line": "bank",
"acct_txn_cnt_24h": 12,
"txn_amount": 9999.99,
"acct_txn_sum_24h": 60000
}
这条文档应该命中 T02。特征在上游算好、规则在引擎实时命中,这套分法才让整条链路真正具备落地性。
多规则同时命中的验证结果 #
真实风控里,一个事件往往不只命中一条规则。这次混合样本验证里,我们构造了更接近真实业务流的样本:
| 文档 ID | 命中规则 | 最高风险等级 |
|---|---|---|
bank_multi_1 | T01、T04、T05、T06 | HIGH |
aml_multi_1 | A01、A02、A03 | HIGH |
security_login_multi_1 | S01、S02、S03、S05 | HIGH |
security_txn_1 | S04 | HIGH |
credit_multi_1 | C01、C03、C03B | HIGH |
insurance_multi_1 | I01、I02、I03、I04、I05 | HIGH |
safe_bank_1 | 无命中 | 无 |
safe_login_1 | 无命中 | 无 |
这组结果比逐条 demo 验证更有实际参考价值。它说明规则在混合业务流里能稳定输出结果,也能正确识别正常事件。
输出结果的格式 #
命中后的输出不只是一个 tag。下面是一个大额转账样本在写入后的实际结果:
{
"risk_tags": [
"#0#T01|HIGH|bank|大额转账触发",
"#4#T04|MEDIUM_HIGH|bank|深夜首次对手大额转账",
"#5#T05|HIGH|bank|新账户当日大额流出",
"#6#T06|LOW|bank|整数金额偏好且对手新增"
],
"risk_repo_id": "fintech_risk_20260415_demo",
"risk_matched": true,
"risk_hit_count": 4,
"risk_rule_ids": ["T01", "T04", "T05", "T06"],
"risk_levels": ["HIGH", "MEDIUM_HIGH", "HIGH", "LOW"],
"risk_level_max": "HIGH",
"risk_biz_lines": ["bank", "bank", "bank", "bank"],
"risk_titles": [
"大额转账触发",
"深夜首次对手大额转账",
"新账户当日大额流出",
"整数金额偏好且对手新增"
]
}
未命中时输出:
{
"risk_repo_id": "fintech_risk_20260415_demo",
"risk_matched": false,
"risk_hit_count": 0,
"risk_rule_ids": [],
"risk_levels": [],
"risk_biz_lines": [],
"risk_titles": []
}
下游系统拿到这些字段可以直接做决策:risk_matched 为 true 就进入风控分支,risk_level_max 为 HIGH 就拦截或进入高风险队列,risk_rule_ids 和 risk_titles 直接用于审计记录和人工复核界面。
在 Easysearch 上怎么接入 #
这次验证走通的资源名如下:
| 资源类型 | 名称 |
|---|---|
| 规则库 | fintech_risk_20260415_demo |
| Ingest Pipeline | fintech_risk_demo |
| 索引模板 | fintech_risk_events_demo |
| Demo 索引 | fintech-risk-events-demo-2026.04.15 |
整条链路的路径:导入规则到规则库 → 编译规则 → 创建带默认 pipeline 的索引模板 → 上游把特征化事件文档写入业务索引 → 下游读取结构化风险字段执行处置。
有两个前置条件要保证:规则库必须先 _compile,业务写入前规则依赖的特征字段必须已经准备好。
写入时直接向索引发文档即可:
POST /fintech-risk-events-demo-2026.04.15/_doc/bank_multi_1
因为索引模板里已经设置了默认 pipeline:
{
"index.default_pipeline": "fintech_risk_demo"
}
对应的 pipeline 逻辑也很直接:先执行规则匹配,再补充规则库标识,最后把命中标签展开成结构化风险字段。精简后的定义如下:
{
"processors": [
{
"check_match_rules": {
"rules_id": "fintech_risk_20260415_demo",
"match_field": "risk_tags"
}
},
{
"set": {
"field": "risk_repo_id",
"value": "fintech_risk_20260415_demo"
}
},
{
"script": {
"lang": "javascript",
"source": "把 risk_tags 解析成 risk_matched、risk_hit_count、risk_rule_ids、risk_level_max 等结构化字段"
}
}
]
}
所以不需要额外带 ?pipeline= 参数。上游调用保持简单,接入方不需要感知规则引擎的存在,规则匹配能力直接沉到写入链路里。
为什么这套方式适合银行和保险 #
银行和保险场景有几个共同特点,让规则引擎比其他方式更适合承担实时风控的底层。
大额交易、深夜交易、短期出险、频繁理赔,这些风险本身就有明确阈值,不是模糊信号。这类风险最怕的不是识别不出来,而是识别得太晚。
监管口径变化、业务流程调整、新出现的欺诈手法,都会持续推着规则修改。如果每次改规则都得改代码重发版,系统迭代速度会跟不上业务变化。
银行和保险场景里,很多决策需要复核、回溯和审计。规则命中的结果天然有解释性——命中了哪条规则、属于哪类风险、最高等级是什么,这比逻辑散落在代码和 ETL 脚本里清楚太多。
一个实际的建议 #
不需要把所有风控都交给模型。在银行和保险场景里,更稳的分工是:上游把窗口聚合和画像特征算好,Easysearch 规则引擎负责实时命中和结构化打标,模型再处理更复杂、更模糊的风险模式。
规则引擎不是模型的替代,是实时风控链路里最应该先补齐的那层。
如果你正在做银行或保险风控,可以先抽 10 到 20 条最典型的规则,把上游已有的聚合特征写进事件文档,在 Easysearch 上跑一轮规则导入、编译和样本验证。跑完你会知道现有的风控逻辑有多少能从代码里抽出来,哪些风险可以先用规则快速兜住。
规则引擎功能当前需要试用 License,可以先下载 Easysearch:https://infinilabs.cn/download,再联系售前申请试用 License 并获取开通指引。











