



 400-139-9200
400-139-9200


本文诣在简单介绍 Flight SQL 的诞生背景、缘由,并不涉及其中的具体实现等技术细节。
列存的时代 #
大数据时代,以数据分析为主的场景下,人们不再关心整个实体,而仅仅关注其中的某个属性,这种情况下,如果数据在磁盘上按行存储,我们需要将所有行都从磁盘上读取出来,但仅仅用其中某列的一小部分数据,造成 I/O 浪费。如果数据是按列存放在磁盘上的,那我们仅需要读取所需列在磁盘上占用的一小块数据,大大节省了磁盘 I/O。
此外,由于列存是将相同列存放到一起,其具有相同的数据类型,相较于行存将不同类型的数据存放到一起,列存可以达到更好的压缩效果。
列存时代下仍然是行存的基础设施 #
现在是列存的时代,许多数据库在积极地拥抱列存来满足数据分析场景下的需求,但我们的基础设施却仍是以行存为主的。比如,数据库 client 与 server 通讯的协议。
JDBC 和 ODBC 是在行存时代下常见的基于行存的通讯协议,在之前 client 和 server 都是基于行存的情况下,这是没有问题的:
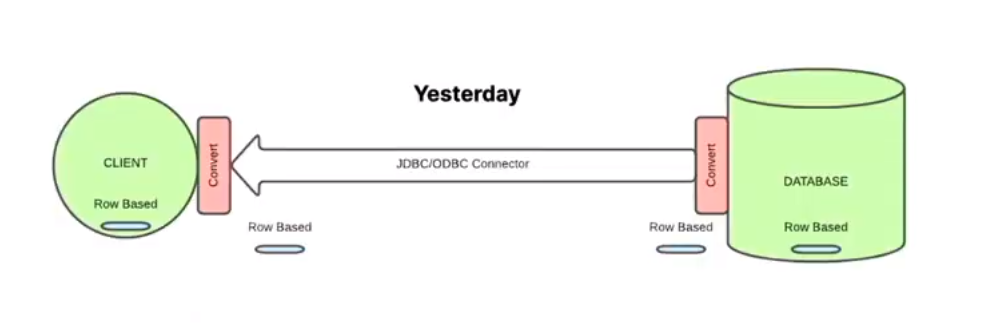
但在如今 client 和 server 都积极拥抱列存的情况下,就没有那么好了。为了使用 JDBC/ODBC,数据从 server 传到 client 时必须先转换为行存格式,以便被 JDBC/ODBC 传输,当数据传到 client 后,client 又必须将行存数据转化为列存数据,才可以进行处理。这其中行存与列存的转换,是序列化与反序列化的过程,其开销并不小。

我们完全可以避免这种不必要的转换,如果我们的传输协议也是基于列存的。
使用列存格式进行数据传输 #
![]()
Apache Arrow 作为现如今广为应用的内存列存格式,为什么不做一个基于 Arrow 的传输协议呢,Apache Arrow 社区也是这么想的,所以 Apache Flight 应运而生。
那什么是 Flight SQL #
我们已经知道了什么是 Flight,那为什么又有了 Flight SQL? 因为:
- Flight client 和 server 通讯发送的仅仅是一串字节
- Flight 支持任何表格数据(tabular data),而非专门针对数据库
所以我们可以发现 Flight 其实是一种比较通用的协议,对于数据库的操作而言,它并不能被称为一种标准,Flight SQL 就是在 Flight 基础之上,对 SQL 提供专有支持的 SQL 数据库通讯协议。
除了解决了无必要的数据转换问题外,一个标准的通讯协议还可以做到数据库无关,只要数据库支持了 Flight SQL,那么就可以使用 client 与其进行通信,无需像 JDBC/ODBC 那样,为每一个数据库都安装一个 driver,从而做到 1:n 的支持。
各家数据库对 Flight SQL 支持 #
- Databend: https://github.com/datafuselabs/databend/issues/10745 Databend 已经开始着手实现对 Flight SQL 的 server 端支持
- TIDB: https://github.com/pingcap/tidb/issues/21056
TIDB 社区并没有积极推进这件事,大概因为:
- Flight SQL 仍未成熟,尤其是在这个 Issue 创建的时间: 2020 年
- TIDB 内部,实现了与 RecordBatch 相类似的列存数据结构 chunk
- TIDB 与 TIKV 的通讯,采用的实现与 Flight 类似,换到一个类似的东西去,可能收益不大
参考 #










